In today’s post, we’re going to solve an interesting Cryptography challenge.
In the challenge, we’re given the following Ciphertext, and our task is to crack it in order to recover the Plaintext and Key.

The point is simple, cracking the given Ciphertext and the key, knowing that the cipher was encrypted using a repeating multi-byte XOR key.
Let’s start with some theory first.
The algorithm I’m going to use to solve the challenge is a statistical approach.
It basically constitutes of the following steps:
- Get the biggest English freely available library/book online to build the English letters histogram.
- I’m assuming that the plaintext is in English. Otherwise, this approach won’t work.
- This step is very useful when working with Cryptography challenges, trust me, it really is!
- Measure the hamming distances between consecutive sequences of bytes.
- In that step, I’ll be using windows of X bytes, then X+1, then X+2, until N, where N is a random number that’s big enough to give us enough sample size (and therefore enough variance) to normalize the Hamming Weights of the bytes.
- The KEYSIZE values with the top scores are the potential correct KEYSIZE that could be used to bruteforce the correct key size.
- Divide the ciphertext into KEYSIZE blocks worth of bytes.
- Transpose the blocks to get the final matrix to be cracked.
- If this step makes no sense, get a pencil and a paper, and think about it.
- We already know that the ciphertext was encrypted using a repeating XOR key, now imagine having the correct key size, dividing the ciphertext into blocks in that length would provide us with groups of bytes, each of which is encrypted using the same key.
- Now the transposing step should make perfect sense, the resultant matrix would be blocks, each is encrypted using a One-Byte XOR, that is (relatively) easy to break.
- Crack each block using One-Byte XOR algorithm, compare the result statistically with the English histogram we built to see the likelyhood of the correct bytes.
- Statistically analyze all the output, bring all the top candidate cracked bytes together and you should be able to notice a readable pattern.
Enough theory, let’s dive into the coding part (and feel the pain).
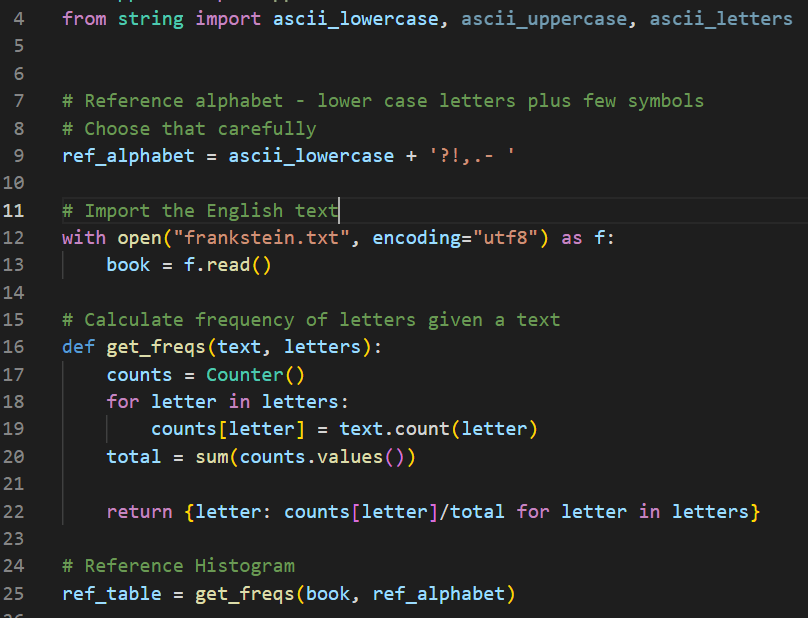
Step1. Building An Efficient English Histogram
We can do that through any huge valid English text, I’ll keep it simple and head to an online free novels/ebooks website and download a decent big PDF. Here are the top downloaded ebooks per unit time, you can pick whatever you want (the bigger the text, the more accurate the histogram will be).
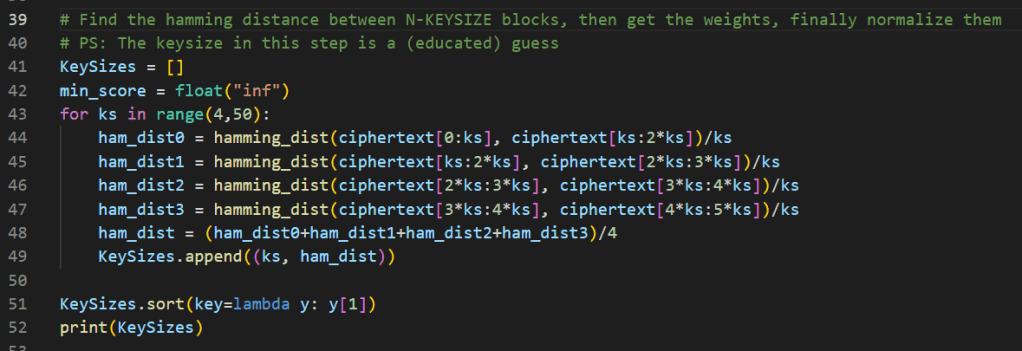
Step2. Hamming Distance
That’s an easy one, we will get the Hamming Weight for each distance, normalize the weights, and this is going to be the score for a given KEYSIZE.
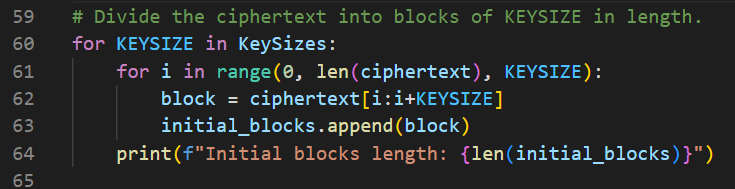
Step3. Divide the Ciphertext into KEYSIZE-length Blocks
We can apply that method to the top three, four, or otherwise X number of the candidate key sizes from the last step. I’ll just iterate over all of them.
Step4. Transposing the Blocks’ Matrix
Group together the N’th byte in each block into a new block, respectively.

Step5. Crack The Individual Transposed Blocks
This is a normal One-Byte XOR Key cracking, and for the sake of autonomy, I’m going to use the English Histogram to score each output statistically.
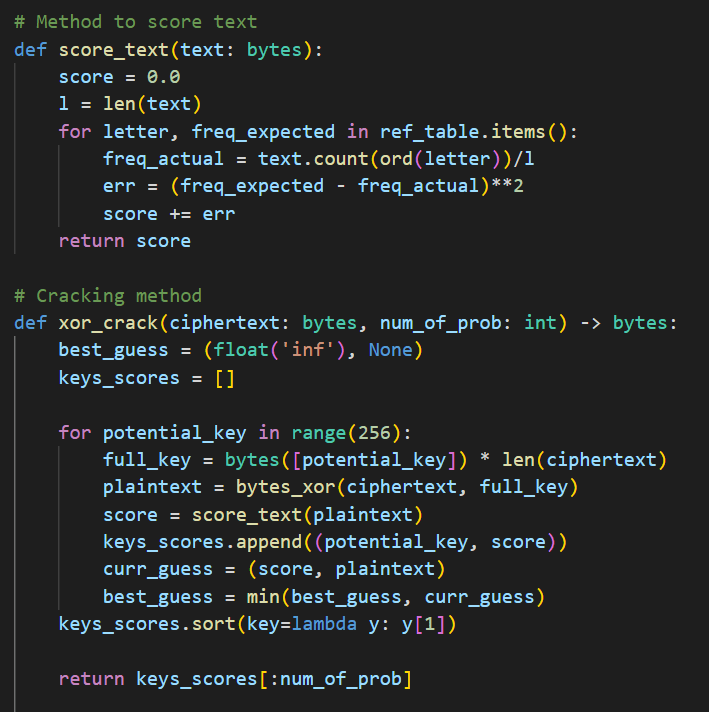
Finally, apply the algorithm against the transposed blocks.
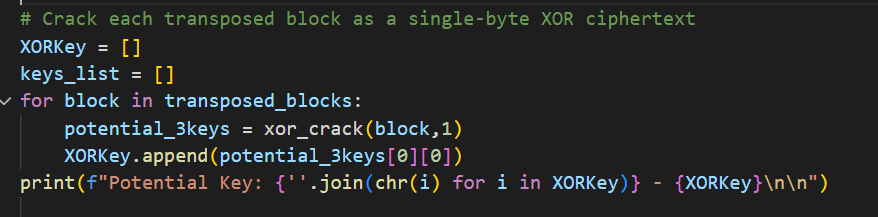
Applying the steps, we should be able to break the ciphertext and get the plaintext and the key.

